通過視圖合成增強預訓練2D擴散模型的可擴展技術
隨著生成式人工智能的快速發展,擴散模型已成為圖像合成領域的重要支柱。傳統的2D擴散模型雖然在單視圖圖像生成上表現出色,但在生成具有空間一致性的多視角圖像或理解三維場景結構方面仍面臨挑戰。通過視圖合成技術來增強預訓練的2D擴散模型,已成為一個備受關注的研究方向,它不僅能夠有效利用現有的大規模2D數據預訓練成果,還能為模型注入三維理解能力,推動計算機視覺與圖形學在軟硬件技術開發中的創新應用。
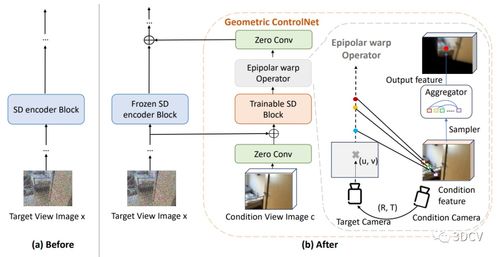
視圖合成增強技術的核心思想,是利用多視角圖像數據或三維幾何信息,引導預訓練的2D擴散模型學習場景的空間一致性表示。一種常見的方法是構建一個聯合訓練框架,其中2D擴散模型作為基礎生成器,而視圖合成模塊則負責建立不同視角間的幾何約束。例如,通過引入基于極線幾何的損失函數,模型在生成新視角圖像時,能夠保持與源視角在三維結構上的一致性。一些研究還探索了將神經輻射場(NeRF)等隱式三維表示與擴散模型相結合,通過可微渲染將3D一致性約束反向傳播到2D生成過程中,從而在無需顯式3D監督的情況下,提升模型對物體形狀和外觀的建模能力。
該技術的可擴展性主要體現在以下幾個方面:它能夠充分利用互聯網上豐富的大規模2D圖像數據集進行預訓練,避免了收集大量精準3D數據的昂貴成本。通過引入輕量級的視圖合成適配器,可以在不顯著增加模型參數量的情況下,將現有的強大2D擴散模型(如Stable Diffusion)升級為具備多視角生成能力的系統。這種增強是模塊化的,視圖合成組件可以根據具體任務需求進行靈活替換或優化,例如針對人臉、室內場景或自然景觀等不同領域,采用特定的三維表示方法。隨著擴散模型本身架構的演進(如潛在擴散模型),視圖合成技術可以與之協同發展,通過改進訓練策略(如分數蒸餾采樣)或引入更高效的注意力機制,進一步提升生成質量和計算效率。
在計算機軟硬件技術開發層面,這項技術帶來了新的機遇與挑戰。軟件方面,它推動了開源框架(如Diffusers庫)的擴展,支持多模態3D內容生成工具的集成,使得開發者能夠更容易地構建從文本或單圖像生成三維模型的應用。算法優化上,研究人員正在探索如何減少視圖合成中的推理時間,例如通過緩存機制、知識蒸餾或開發專用的加速采樣器。硬件層面,由于視圖合成增強通常涉及大量的矩陣運算和迭代優化,它對GPU顯存和并行計算能力提出了更高要求。這促使硬件廠商和云計算平臺優化針對擴散模型和神經渲染的算力支持,例如開發專用AI加速芯片或提供優化的推理服務。邊緣設備上的輕量化部署也成為重要課題,通過模型壓縮、量化技術和自適應計算,使增強后的模型能夠在移動端或嵌入式系統中實時運行,賦能AR/VR、機器人導航等新興應用。
通過視圖合成增強預訓練2D擴散模型的技術,正朝著更高保真度、更強可控性和更廣適用性的方向發展。結合新興的物理仿真與生成式先驗,它有望在虛擬內容創作、數字孿生、自動駕駛模擬等領域發揮更大作用。隨著軟硬件技術的持續協同創新,這一技術路徑將不僅推動生成式AI本身的進步,也為三維視覺與圖形學的實際落地開辟了可擴展且高效的實踐道路。
如若轉載,請注明出處:http://www.yanjuji.com.cn/product/74.html
更新時間:2026-02-24 13:38:50